引言:
在信息大爆炸的今天,有了搜索引擎的帮助,使得我们能够快速,便捷的找到所求。提到搜索引擎,就不得不说VSM模型,说到VSM,就不得不聊倒排索引。可以毫不夸张的讲,倒排索引是搜索引擎的基石。
VSM检索模型
VSM全称是Vector Space Model(向量空间模型),是IR(Information Retrieval信息检索)模型中的一种,由于其简单,直观,高效,所以被广泛的应用到搜索引擎的架构中。98年的Google就是凭借这样的一个模型,开始了它的疯狂扩张之路。废话不多说,让我们来看看到底VSM是一个什么东东。
在开始之前,我默认大家对线性代数里面的向量(Vector)有一定了解的。向量是既有大小又有方向的量,通常用有向线段表示,向量有:加、减、倍数、内积、距离、模、夹角的运算。
文档(Document):一个完整的信息单元,对应的搜索引擎系统里,就是指一个个的网页。
标引项(Term):文档的基本构成单位,例如在英文中可以看做是一个单词,在中文中可以看作一个词语。
查询(Query):一个用户的输入,一般由多个Term构成。
那么用一句话概况搜索引擎所做的事情就是:对于用户输入的Query,找到最相似的Document返回给用户。而这正是IR模型所解决的问题:
信息检索模型是指如何对查询和文档进行表示,然后对它们进行相似度计算的框架和方法。
举个简单的例子:
现在有两篇文章(Document)分别是 “春风来了,春天的脚步近了” 和 “春风不度玉门关”。然后输入的Query是“春风”,从直观上感觉,前者和输入的查询更相关一些,因为它包含有2个春,但这只是我们的直观感觉,如何量化呢,要知道计算机是门严谨的学科^_^。这个时候,我们前面讲的Term和VSM模型就派上用场了。
首先我们要确定向量的维数,这时候就需要一个字典库,字典库的大小,即是向量的维数。在该例中,字典为{春风,来了,春天, 的,脚步,近了,不度,玉门关} ,文档向量,查询向量如下图:
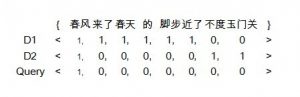
PS:为了简单起见,这里分词的粒度很大。
将Query和Document都量化为向量以后,那么就可以计算用户的查询和哪个文档相似性更大了。简单的计算结果是D1和D2同Query的内积都是1,囧。当然了,如果分词粒度再细一些,查询的结果就是另外一个样子了,因此分词的粒度也是会对查询结果(主要是召回率和准确率)造成影响的。
上述的例子是用一个很简单的例子来说明VSM模型的,计算文档相似度的时候也是采用最原始的内积的方法,并且只考虑了词频(TF)影响因子,而没有考虑反词频(IDF),而现在比较常用的是cos夹角法,影响因子也非常多,据传Google的影响因子有100+之多。
大名鼎鼎的Lucene项目就是采用VSM模型构建的,VSM的核心公式如下(由cos夹角法演变,此处省去推导过程)

VSM模型公式
从上面的例子不难看出,如果向量的维度(对汉语来将,这个值一般在30w-45w)变大,而且文档数量(通常都是海量的)变多,那么计算一次相关性,开销是非常大的,如何解决这个问题呢?不要忘记了,我们这节的主题就是 倒排索引,主角终于粉墨登场了!!!
倒排索引
倒排索引非常类似我们前面提到的Hash结构。以下内容来自维基百科:
倒排索引(英语:Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。
有两种不同的反向索引形式:
- 一条记录的水平反向索引(或者反向档案索引)包含每个引用单词的文档的列表。
- 一个单词的水平反向索引(或者完全反向索引)又包含每个单词在一个文档中的位置。
由上面的定义可以知道,一个倒排索引包含一个字典的索引和所有词的列表。其中字典索引中包含了所有的Term(通俗理解为文档中的词),索引后面跟的列表则保存该词的信息(出现的文档号,甚至包含在每个文档中的位置信息)。下面我们还采用上面的方法举一个简单的例子来说明倒排索引。
例如现在我们要对三篇文档建立索引(实际应用中,文档的数量是海量的):
文档1(D1):中国移动互联网发展迅速
文档2(D2):移动互联网未来的潜力巨大
文档3(D3):中华民族是个勤劳的民族
那么文档中的词典集合为:{中国,移动,互联网,发展,迅速,未来,的,潜力,巨大,中华,民族,是,个,勤劳}
建好的索引如下图:
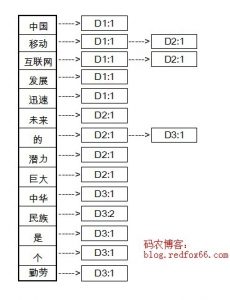
在上面的索引中,存储了两个信息,文档号和出现的次数。建立好索引以后,我们就可以开始查询了。例如现在有一个Query是”中国移动”。首先分词得到Term集合{中国,移动},查倒排索引,分别计算query和d1,d2,d3的距离。有没有发现,倒排表建立好以后,就不需要在检索整个文档库,而是直接从字典集合中找到“中国”和“移动”,然后遍历后面的列表直接计算。
对倒排索引结构我们已经有了初步的了解,但在实际应用中还有些需要解决的问题(主要是由海量数据引起的)。笔者列举一些问题,并给出相应的解决方案,抛砖以引玉,希望大家可以展开讨论:
1.左侧的索引表如何建立?怎么做才能最高效?
可能有人不假思索回答:左侧的索引当然要采取hash结构啊,这样可以快速的定位到字典项。但是这样问题又来了,hash函数如何选取呢?而且hash是有碰撞的,但是倒排表似乎又是不允许碰撞的存在的。事实上,虽然倒排表和hash异常的相思,但是两者还是有很大区别的,其实在这里我们可以采用前面提到的Bitmap的思想,每个Term(单词)对应一个位置(当然了,这里不是一个比特位),而且是一一对应的。如何能够做到呢,一般在文字处理中,有很多的编码,汉字中的GBK编码基本上就可以包含所有用到的汉字,每个汉字的GBK编码是确定的,因此一个Term的”ID”也就确定了,从而可以做到快速定位。注:得到一个汉字的GBK号是非常快的过程,可以理解为O(1)的时间复杂度。
2.如何快速的添加删除更新索引?
有经验的码农都知道,一般在系统的“做加法”的代价比“做减法”的代价要低很多,在搜索引擎中中也不例外。因此,在倒排表中,遇到要删除一个文档,其实不是真正的删除,而是将其标记删除。这样一个减法操作的代价就比较小了。
3.那么多的海量文档,如果存储呢?有么有什么备份策略呢?
当然了,一台机器是存储不下的,分布式存储是采取的。一般的备份保存3份就足够了。
好了,倒排索引终于完工了,不足的地方请指正。谢谢
做人要厚道,转载请注明出处:http://diducoder.com/mass-data-topic-8-inverted-index.html
喜欢!赞一个!希望有机会想博主请教一下算法上的知识!
不错,支持博主,希望能很快看到后续文章。
请问下,比如中国 gbk编码后的ID是多少?
那中国人呢?
用bitmap的思想 ID会不会太大了啊?
GBK编码是以字为单位的,以此为单位,要将字的GBK编码转变成词(可以适当的做些运算),这样得到的ID就可以作为Term的标识。
hi,楼主,这篇文章对我来说很有用。现在我正在写一个小的搜索,在思考的过程中,遇到些问题,想向您请教一下:
1.对于海量数据,生成倒排索引。每一个word中包含一个doc列表,在这个doc中又有这个word出现的位置的hit列表。预估这个数据是很大的,内存里放不下,那如果在有限的硬件条件下,如果doc只能加载一部分到内存中,如何设计这个缓存机制来保证不在内存中的数据能够快速读取呢。希望能看到楼主这方面的精彩解释。
内存中是肯定放不下的,而且如果检索系统稍微大一些的话,一台机器是放不下的,这时候就需要分布式集群计算了。你的这种情况缓存是必须采取的,最近最多使用是个不错的机制。这方面的东西已经有开源的项目了,比如memcache,你可以研究下。
引用通告: 海量数据处理专题(一)——开篇 | 帝都码农
老师您好,我是北航出版社的图书策划编辑,看到您有很多技术博文,想问下您有兴趣写书吗?望回复,谢谢。